12月30日,杨尔弘教授出席北京智源人工智能研究院自然语言处理前沿技术开放日活动,并汇报了汉语学习者文本多维标注数据集建设的最新成果。智能辅助语言学习是跨自然语言理解与生成两个方面的研究任务,对学习者产生的文本进行错误识别、并修改成为符合母语习惯的语句,需要知识指导。本数据集包含2000余篇汉语学习者文本,共计30000余句,由北京语言大学BLCU-ICALL组组织开发,召集具有汉语国际教育专业背景的标注人员对文本中的错误进行标注、改正,并给出语句的流利程度,形成具有多维信息的标注数据集,可服务于汉语自动语法纠错与评判,第二语言习得等研究。


标注体系
YACLC V1.0结合了汉语自身的特点,基于粒度为词、最小改动、忠于原意和多维度标注四项标注原则,是一套新的汉语学习者语料库标注体系,其创新点在于:
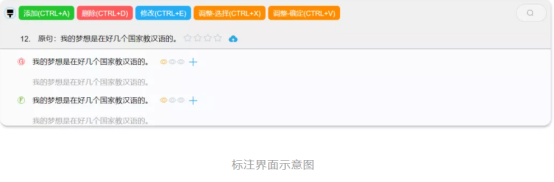
1)设计纠正偏误和提升流利度的标注方式,由多位标注员对同一句子进行标注,提供多维度的多种标注结果;
2)简化偏误类型为成分缺失、成分冗余、词汇误用、语序错误,降低标注难度;
3)对句子进行可接受度评分,并以此限制每种评分对应的标注方式,提升标注质量;
4)基于篇章级别信息,对偏误句的上下文依赖性进行分级标注。
标注实践
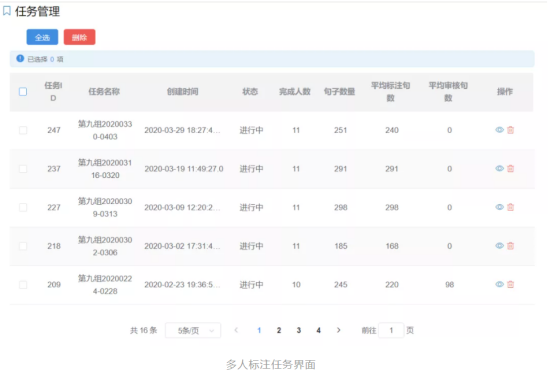
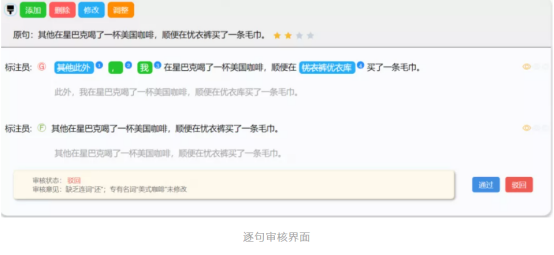
BLCU-ICALL组招募了百余位汉语国际教育、语言学及应用语言学等专业的研究生,组成标注员团队,并搭建了一个可供多人在线的众包标注平台,分阶段地开展偏误标注和审核工作。
YACLC V1.0数据获取
本次发布的汉语学习者文本多维标注数据集YACLC V1.0,其训练集规模为8000条,每条数据包括原始句子及其多种纠偏标注与流利标注;验证集和测试集规模都为1000条 ,每条数据皆包含原始句子及其全部纠偏标注与流利标注。关于数据集详细情况见:
http://cuge.baai.ac.cn/#/dataset?id=21&name=YACLC